การออกแบบระบบ RAG (Retrieval-Augmented Generation) ร่วมกับ AI
RAG (Retrieval-Augmented Generation) เป็นเทคนิคที่ช่วยเพิ่มประสิทธิภาพของ AI โดยการนำข้อมูลภายนอกมาเสริมความสามารถในการตอบคำถามหรือสร้างเนื้อหา ผมจะอธิบายการออกแบบระบบ RAG ร่วมกับ AI ดังนี้
องค์ประกอบหลักของระบบ RAG
- ระบบจัดเก็บข้อมูล (Knowledge Base)
- ฐานข้อมูลเอกสาร/ข้อมูลองค์กร
- Vector Database สำหรับเก็บ embeddings
- ระบบจัดการ metadata และ context
- ส่วนประมวลผลข้อมูล (Processing Pipeline)
- การแปลงเอกสารให้อยู่ในรูปแบบที่เหมาะสม
- การสร้าง embeddings จากข้อความ
- การแบ่งเอกสารเป็นส่วนย่อย (chunking)
- ส่วนค้นคืนข้อมูล (Retrieval Component)
- การค้นหาข้อมูลที่เกี่ยวข้องด้วย semantic search
- การจัดอันดับความเกี่ยวข้องของข้อมูล
- การเลือกข้อมูลที่เหมาะสมที่สุด
- ส่วน AI Generation
- Large Language Model (LLM)
- Prompt engineering
- การผสานข้อมูลที่ค้นคืนได้เข้ากับ prompt
ขั้นตอนการทำงาน
- การเตรียมข้อมูล
- รวบรวมเอกสารที่เกี่ยวข้อง (PDF, HTML, TXT, ฯลฯ)
- แปลงเอกสารเป็นรูปแบบข้อความ
- แบ่งเอกสารเป็นส่วนย่อย (chunks) ขนาดเหมาะสม
- สร้าง embeddings จากแต่ละ chunk ด้วย embedding model
- การจัดเก็บข้อมูล
- บันทึก embeddings ลงใน vector database
- จัดเก็บข้อมูลต้นฉบับและ metadata
- กระบวนการตอบคำถาม
- รับคำถามจากผู้ใช้
- สร้าง embedding ของคำถาม
- ค้นหาเอกสารที่เกี่ยวข้องด้วย vector similarity search
- เลือกเอกสารที่เกี่ยวข้องที่สุด
- สร้าง prompt โดยรวมข้อมูลที่ค้นคืนได้
- ส่ง prompt ไปยัง LLM
- คืนคำตอบให้ผู้ใช้พร้อมอ้างอิงแหล่งที่มา
เทคโนโลยีที่เกี่ยวข้อง
- Vector Databases
- Pinecone, Weaviate, Milvus, Qdrant, Chroma
- เก็บ vector embeddings และให้บริการค้นหาแบบ similarity search
- Embedding Models
- OpenAI Embeddings API
- Sentence Transformers
- HuggingFace Embeddings
- LLM Models
- OpenAI GPT-4/GPT-3.5
- Claude (Anthropic)
- Llama 3, Mistral, Gemini
- เครื่องมือเสริม
- LangChain/LlamaIndex สำหรับจัดการ pipeline
- Document loaders สำหรับอ่านเอกสารรูปแบบต่างๆ
- Text splitters สำหรับแบ่ง chunks
การปรับแต่งและเพิ่มประสิทธิภาพ
- Chunking Strategies
- ขนาด chunk ที่เหมาะสม (ปกติ 512-1024 tokens)
- วิธีการแบ่ง chunk (ตามย่อหน้า, ตามหัวข้อ, แบบทับซ้อน)
- Retrieval Techniques
- BM25 + Vector search (hybrid search)
- Query expansion
- Re-ranking ผลลัพธ์
- Prompt Engineering
- การออกแบบ prompt template ที่มีประสิทธิภาพ
- การกำหนดบทบาทให้ AI
- การกำหนดรูปแบบคำตอบที่ต้องการ
- การประเมินผล
- ความถูกต้องของข้อมูล (factual accuracy)
- ความครบถ้วนของคำตอบ
- การติดตามและปรับปรุงประสิทธิภาพอย่างต่อเนื่อง
ข้อควรพิจารณาในการใช้งานจริง
- ความปลอดภัยของข้อมูล
- การเข้ารหัสข้อมูล
- การจัดการสิทธิ์การเข้าถึง
- การติดตามการใช้งาน (audit logs)
- การทำงานแบบ real-time
- การจัดการกับข้อมูลที่อัปเดตบ่อย
- การปรับ index ในฐานข้อมูล
- ต้นทุนและทรัพยากร
- ค่าใช้จ่ายในการเรียกใช้ API ของ LLM
- ทรัพยากรในการจัดเก็บและประมวลผล embeddings
- การจัดสรรทรัพยากรให้เหมาะสม
- การปรับใช้ให้เข้ากับบริบทเฉพาะ
- การปรับแต่งให้เข้ากับโดเมนเฉพาะ
- การเพิ่ม domain-specific knowledge
- การฝึก fine-tuning LLM (ถ้าจำเป็น)
การนำ RAG มาใช้ร่วมกับ AI เป็นวิธีที่มีประสิทธิภาพในการเพิ่มความถูกต้องและความน่าเชื่อถือของคำตอบ โดยเฉพาะในกรณีที่ต้องการข้อมูลเฉพาะที่อาจไม่มีอยู่ในข้อมูลฝึกของ LLM หรือเป็นข้อมูลที่ต้องการความเป็นปัจจุบัน
ภาพนี้แสดงกระบวนการทำงานของระบบ RAG (Retrieval-Augmented Generation) ร่วมกับ AI แบ่งเป็น 2 ส่วนหลัก
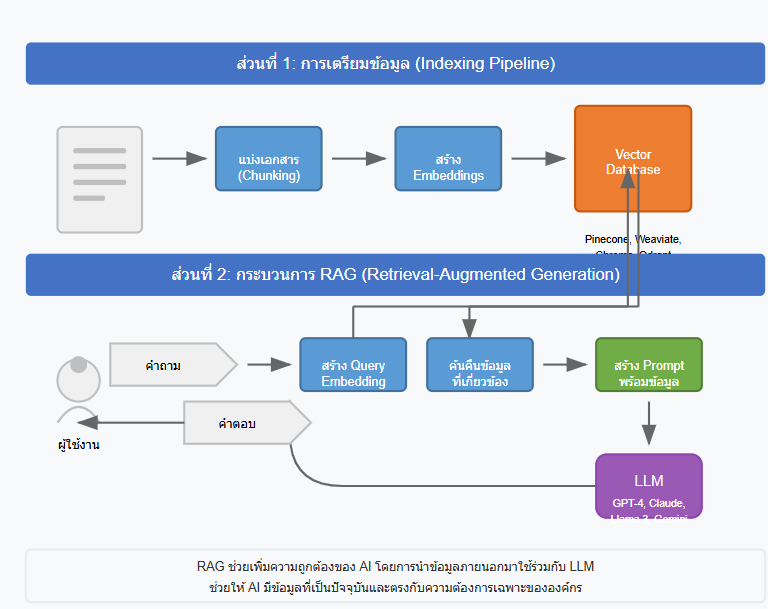
ส่วนที่ 1: การเตรียมข้อมูล (Indexing Pipeline)
- เริ่มจากเอกสารต้นฉบับ (เช่น PDF, HTML, TXT)
- แบ่งเอกสารเป็นส่วนย่อย (Chunking) ขนาดที่เหมาะสม
- สร้าง Embeddings จากข้อความด้วย Embedding Model
- จัดเก็บลงใน Vector Database (เช่น Pinecone, Weaviate, Chroma, Qdrant)
ส่วนที่ 2: กระบวนการตอบคำถาม (Retrieval-Augmented Generation)
- ผู้ใช้ส่งคำถามเข้ามาในระบบ
- ระบบแปลงคำถามเป็น Query Embedding
- ค้นหาข้อมูลที่เกี่ยวข้องจาก Vector Database ด้วย semantic search
- นำข้อมูลที่ค้นได้มาสร้าง Prompt ที่มีข้อมูลประกอบ
- ส่ง Prompt ไปยัง LLM (เช่น GPT-4, Claude, Llama 3, Gemini)
- LLM สร้างคำตอบและส่งกลับไปยังผู้ใช้
ด้วยกระบวนการนี้ AI จะสามารถให้คำตอบที่มีความถูกต้อง เป็นปัจจุบัน และตรงกับบริบทเฉพาะขององค์กรหรือข้อมูลเฉพาะทางที่ต้องการได้อย่างมีประสิทธิภาพ
ขอบคุณ
Nontawatt Saraman