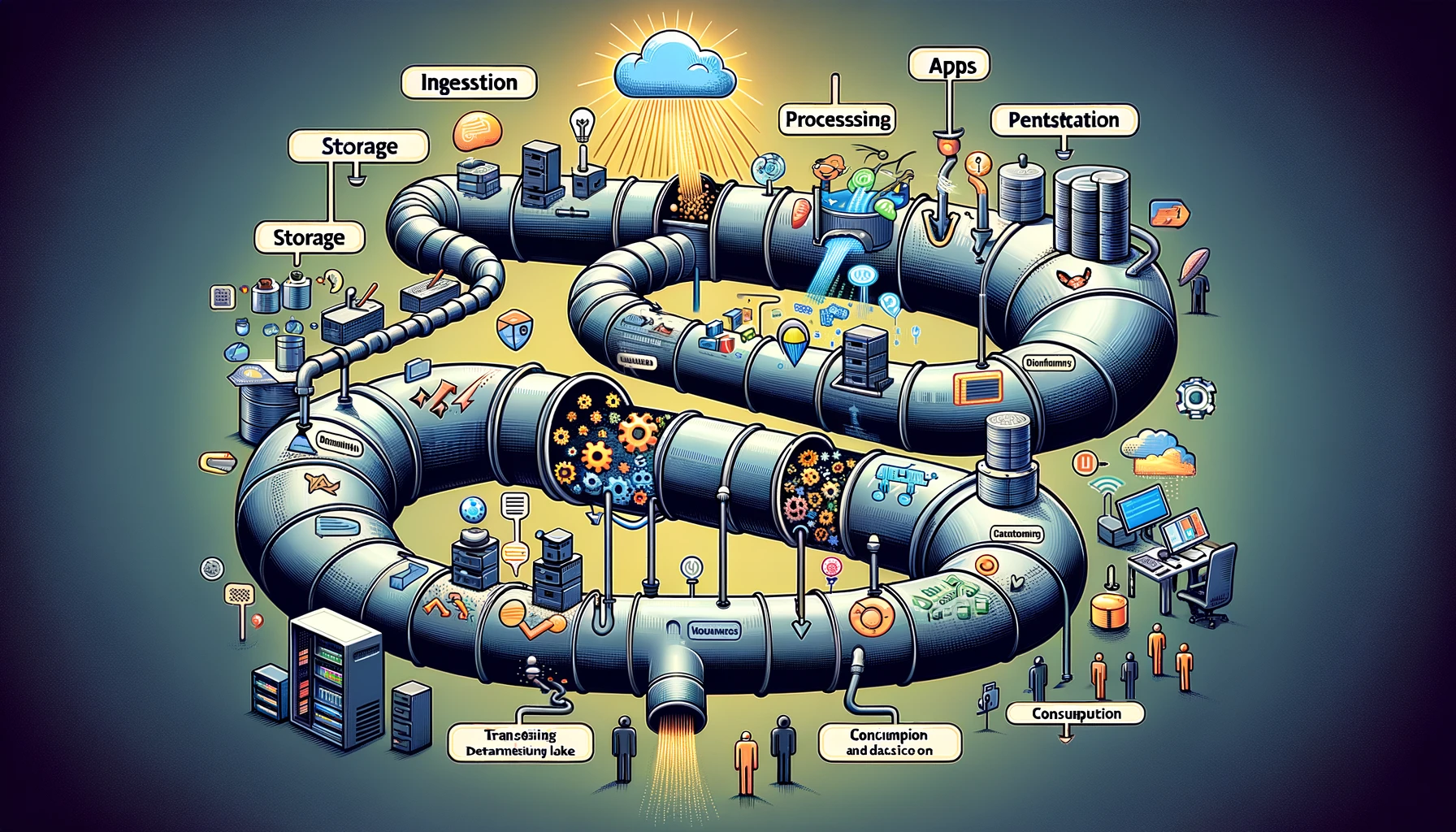

Data pipeline คือชุดขั้นตอน หรือกระบวนการที่ใช้ในการย้ายข้อมูลจากแหล่งที่มา ไปยังปลายทาง เปรียบเสมือนท่อที่ขนส่งข้อมูลจากจุดหนึ่งไปยังอีกจุดหนึ่ง โดยทั่วไปแล้ว data pipeline ประกอบด้วย 4 ขั้นตอนหลัก ดังนี้
- การดึงข้อมูล (Ingestion) ขั้นตอนนี้เป็นการนำข้อมูลจากแหล่งที่มาต่างๆ เช่น ไฟล์ log, แอปพลิเคชัน, เซ็นเซอร์, ฐานข้อมูล ฯลฯ เข้าสู่ data pipeline
- การจัดเก็บข้อมูล (Storage) ข้อมูลที่ดึงเข้ามาจะถูกเก็บไว้ในระบบจัดเก็บข้อมูล เช่น ฐานข้อมูล, data lake, data warehouse ฯลฯ
- การประมวลผลข้อมูล (Processing) ข้อมูลที่เก็บไว้จะถูกนำมาประมวลผล เช่น การกรองข้อมูล การแปลงรูปแบบข้อมูล การวิเคราะห์ข้อมูล ฯลฯ
- การนำข้อมูลไปใช้ (Consumption) ข้อมูลที่ผ่านกระบวนการประมวลผลแล้วจะถูกนำไปใช้งาน เช่น การแสดงผลบนหน้าจอ การวิเคราะห์ทางธุรกิจ การทำนายอนาคต ฯลฯ
องค์ประกอบสำคัญของ data pipeline
เครื่องมือ เครื่องมือที่ใช้ในการดึง จัดเก็บ ประมวลผล และนำข้อมูลไปใช้ เช่น Apache Kafka, Apache Spark, Hadoop, Elasticsearch ฯลฯ
โครงสร้าง โครงสร้างพื้นฐานที่ใช้รองรับ data pipeline เช่น เซิร์ฟเวอร์ คลาวด์ พื้นที่จัดเก็บ ฯลฯ
กระบวนการ กระบวนการทำงานของ data pipeline ตั้งแต่การดึงข้อมูลจนถึงการนำข้อมูลไปใช้
บุคคล บุคคลที่มีหน้าที่ดูแลและจัดการ data pipeline เช่น วิศวกรข้อมูล นักวิเคราะห์ข้อมูล ฯลฯ
ประโยชน์ของ data pipeline
- ช่วยให้สามารถจัดการข้อมูลจำนวนมากได้อย่างมีประสิทธิภาพ
- ช่วยให้สามารถวิเคราะห์ข้อมูลและนำข้อมูลไปใช้ประโยชน์ได้อย่างมีประสิทธิภาพ
- ช่วยให้สามารถตัดสินใจได้อย่างมีข้อมูล
- ช่วยให้สามารถพัฒนาผลิตภัณฑ์และบริการใหม่ๆ
ตัวอย่างการใช้งาน data pipeline
- การวิเคราะห์ log ของเว็บไซต์เพื่อดูว่าผู้ใช้ใช้งานเว็บไซต์อย่างไร
- การวิเคราะห์ข้อมูลการซื้อขายเพื่อดูว่าสินค้าตัวไหนขายดี
- การวิเคราะห์ข้อมูลของเซ็นเซอร์เพื่อตรวจสอบสภาพเครื่องจักร
สรุป
Data pipeline เป็นเครื่องมือสำคัญสำหรับองค์กรที่ต้องการจัดการ วิเคราะห์ และนำข้อมูลไปใช้ประโยชน์ Data pipeline ช่วยให้องค์กรสามารถตัดสินใจได้อย่างมีข้อมูล พัฒนาผลิตภัณฑ์และบริการใหม่ๆ และเพิ่มประสิทธิภาพการทำงาน
สวัสดี
Nontawatt S